Développer une application nécessite, dans la plus part des cas, la gestion d'une certaine quantité de données, c'est pourquoi, bien choisir le mécanisme de sauvegarde des données joue un rôle important dans la réussite de l'application à développer. Ce choix est pris suivant les types des opérations (insertion, modification, suppression et consultation) les plus fréquentes dans l'application, l'architecture technique du système duquel l'application fait partie, le nombre des utilisateurs en accès simultané et plusieurs autres facteurs.
A titre d'exemple, une application qui indique les horaires de prières se caractérise par :
1. Pas d'insertion, de modification, ni suppression des données : l'unique opération est la consultation.
2. Un seul utilisateur sur une seule machine : l'architecture la plus simple.
3. La taille des données est raisonnable : pour chaque ville, les données ne dépassent pas 1Mo.
Ainsi, il est logique de proposer une application avec plusieurs fichiers (un fichier par ville) et les données nécessaires pour une journée (7 date/heures) peuvent être chargées au démarrage et gardées en mémoire.
Ce cas est un exemple très simplifié, (mal)heureusement, la grande majorité des systèmes nécessitent les quatre opérations et impliquent plusieurs utilisateurs au même temps. Dans ces cas, le choix de l'utilisation d'une base des données s'impose (mais nous parlons comme même d'un choix).
Parmi les architectures qui imposent (ou favorisent) l'utilisation d'une base des données, nous trouvons l'architecture Client/serveur. [définition]. Cette architecture se caractérise par sa centralisation, ainsi, penser à mettre en œuvre une seule base des données au centre du système et d'exploiter les possibilités offertes par le SGBD pour mieux gérer les quatre opérations nécessaires devient une solution très raisonnable et bien justifiée.
Cette architecture peut avoir deux formats :
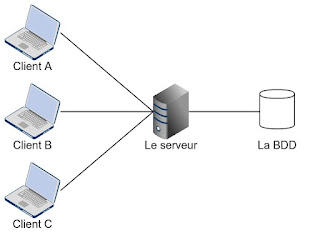
Dans les deux cas, le concepteur doit choisir le bon mécanisme de sauvegarde pour le client et pour le serveur. Dans le premier cas, il n'est pas nécessaire d'opter pour une base des données pour le client; dans le pire des cas, utiliser un fichier peut être suffisant. Néanmoins, le deuxième cas peut encourager la mise au point d'une base des données côté client et d'exécuter toutes les opérations sur cette base des données et la communication entre le client et le serveur se transforme à une opération de synchronisation entre les deux bases des données.
Dans la suite, je vais parler du premier cas avec une base des données centralisées. Ce cas est très répondu vu que l'un des intérêts de l'architecture Client/Serveur est la centralisation. Ainsi, il est rare de trouver des clients avec une grande quantité des données qui nécessite la mise au point d'une base des données côté client. Par conséquent, toutes les opérations (requêtes) et les données manipulées (les réponses à ces requêtes) vont être transmises via le réseau (avec l'évolution des réseaux locaux et les débits qui atteignent 1Go/S ce n'est plus un véritable problème).
Mais, une bonne mise au point de cette architecture nécessite le respect d'une condition importante : pas d'accès directe à la base des données à partir du client; la base des données se connecte exclusivement au serveur.
Le non-respect de cette condition change complètement l'architecture de l'application vers une architecture en 1 tier avec des accès simultanés à la base des données ce qui implique, au moins, les deux faits suivants :

A titre d'exemple, une application qui indique les horaires de prières se caractérise par :
1. Pas d'insertion, de modification, ni suppression des données : l'unique opération est la consultation.
2. Un seul utilisateur sur une seule machine : l'architecture la plus simple.
3. La taille des données est raisonnable : pour chaque ville, les données ne dépassent pas 1Mo.
Ainsi, il est logique de proposer une application avec plusieurs fichiers (un fichier par ville) et les données nécessaires pour une journée (7 date/heures) peuvent être chargées au démarrage et gardées en mémoire.
Ce cas est un exemple très simplifié, (mal)heureusement, la grande majorité des systèmes nécessitent les quatre opérations et impliquent plusieurs utilisateurs au même temps. Dans ces cas, le choix de l'utilisation d'une base des données s'impose (mais nous parlons comme même d'un choix).
Parmi les architectures qui imposent (ou favorisent) l'utilisation d'une base des données, nous trouvons l'architecture Client/serveur. [définition]. Cette architecture se caractérise par sa centralisation, ainsi, penser à mettre en œuvre une seule base des données au centre du système et d'exploiter les possibilités offertes par le SGBD pour mieux gérer les quatre opérations nécessaires devient une solution très raisonnable et bien justifiée.
Cette architecture peut avoir deux formats :
- Un client sans (ou bien avec peu) de données locales,
- Un client avec des données locales.
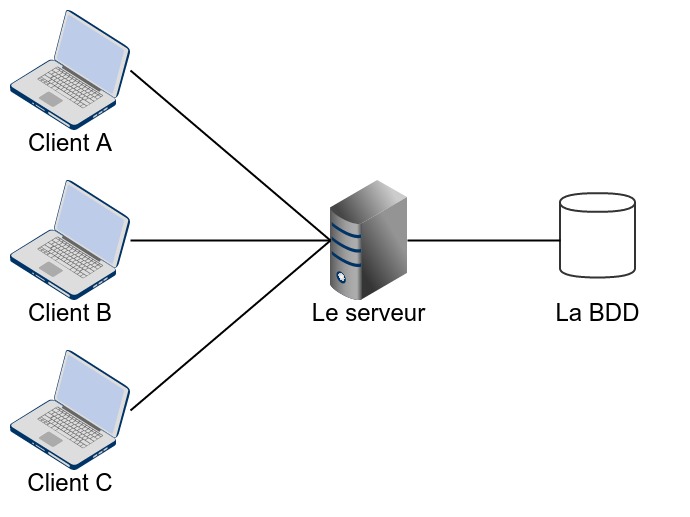
Dans les deux cas, le concepteur doit choisir le bon mécanisme de sauvegarde pour le client et pour le serveur. Dans le premier cas, il n'est pas nécessaire d'opter pour une base des données pour le client; dans le pire des cas, utiliser un fichier peut être suffisant. Néanmoins, le deuxième cas peut encourager la mise au point d'une base des données côté client et d'exécuter toutes les opérations sur cette base des données et la communication entre le client et le serveur se transforme à une opération de synchronisation entre les deux bases des données.
Dans la suite, je vais parler du premier cas avec une base des données centralisées. Ce cas est très répondu vu que l'un des intérêts de l'architecture Client/Serveur est la centralisation. Ainsi, il est rare de trouver des clients avec une grande quantité des données qui nécessite la mise au point d'une base des données côté client. Par conséquent, toutes les opérations (requêtes) et les données manipulées (les réponses à ces requêtes) vont être transmises via le réseau (avec l'évolution des réseaux locaux et les débits qui atteignent 1Go/S ce n'est plus un véritable problème).
Mais, une bonne mise au point de cette architecture nécessite le respect d'une condition importante : pas d'accès directe à la base des données à partir du client; la base des données se connecte exclusivement au serveur.
Le non-respect de cette condition change complètement l'architecture de l'application vers une architecture en 1 tier avec des accès simultanés à la base des données ce qui implique, au moins, les deux faits suivants :

- La montée en charge sur la base des données : il est possible de régler ce problème au niveau de l'application serveur, mais, une connexion directe à la base des données par les clients veut dire que l'application serveur ne peut plus contrôler la charge imposée sur la base des données.
- La gestion des utilisateurs se déplace vers le SGBD : cela impose des conditions supplémentaires sur le SGBD à utiliser. Des SGBD sans une gestion avancées des utilisateurs et des droits d'accès tels que Microsoft Access et Open(Libre)Office Base deviennent inutilisables.
Aucun commentaire:
La publication de nouveaux commentaires n'est pas autorisée.